My AI improved its own working process this week. Not the model. The process. That is the part that matters.
The setup: an LLM reconstructs the documentation of an existing codebase. 43,000 lines of Python, the CLI tool Mistral Vibe. Four named pieces, each doing a different job.
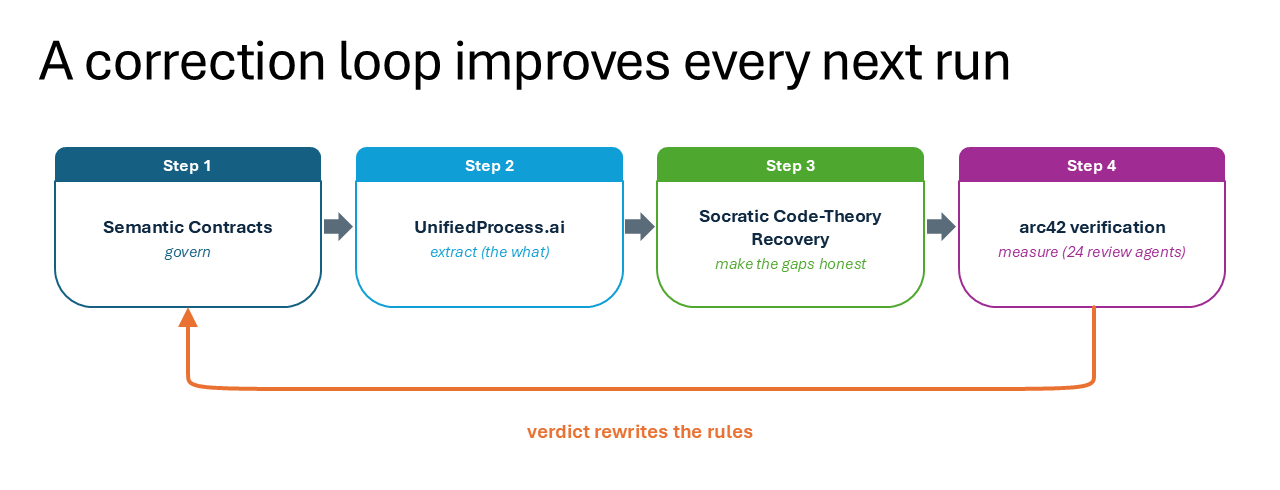
Four pieces, each doing a different job
Semantic Contracts are the written rules the AI works by. They are the layer everything else runs under.
Simon Martinelli's UnifiedProcess.ai extracts the what: use cases and an entity model, fast and grounded in the code.
Socratic Code-Theory Recovery adds the why. Its Question Tree recovers the program's theory in Naur's sense, and separates what the code can answer from what only the team knows. Every leaf is either ANSWERED with a file-and-line reference, or marked OPEN. That honesty is what stops the AI from inventing answers.
Matthias Nissen's arc42agentic then verifies the result: 24 review agents grade the generated arc42 document, chapter by chapter. Without an independent measurement, there is nothing to correct toward.
They are not redundant. They stack: govern, extract, make the gaps honest, measure.
The loop in action
Run 4: verdict RED. Cause: Chapter 10, Quality Requirements, was effectively empty. The AI had marked everything "the team must answer this."
Was that right? No. Timeouts, token budgets, retry policies: those are measurable in the code. The AI had written off too much as unanswerable.
That finding was not clicked away. It became a GitHub issue against the Semantic Contracts. One line was added: derive quality scenarios from measurable code behaviour, do not blanket-mark them open.
Run 5, same codebase, same pipeline: verdict YELLOW. Chapter 10: GREEN. Twelve quality scenarios, each with a file-and-line reference. No invented number.
The verdict rewrites the rules
This is the chain: Semantic Contracts govern, UnifiedProcess.ai extracts, Socratic Code-Theory Recovery makes the gaps honest, arc42 verification measures. The verdict from the last link rewrites the first. That bend-back is the loop. I ratify every rule change. The human stays in the loop.
A better prompt improves one run. A correction loop improves every next run.
LinkedWild